Week1 Day2 的任务:
实现 Memtable 的 iterator
实现 merge iterator
实现 Memtable 的读路径 scan
Tasks
Task1: Memtable Iterator
在前一章里已经实现了 get 的 API,并且可以创建可变与不可变的 memtable。这里首先是给单个的 memtable 创建 iterator,然后将所有 memtable 的 iterator 合并,最后实现 iterator 的范围遍历。
所有的 LSM iterators 都实现了 StorageIterator 的特性,包含 key、value、next 和 is_valid 等方法。为了避免系统过于复杂,这里并不想在我们的 iterator 里拥有类似 Vec 或者 SkipMap 的生命周期。如果没有生命周期泛型参数,我们需要确保无论什么时候使用 iterator,都不应该释放底层的 skiplist 对象。一种解决的方法是:将 Arc<SkipMap> 对象放在 iterator 自身内部。这样需要保证 iterator 与 map 的生命周期一致。这里采用了自我引用结构:1
2
3
4
5
6
7
8
9
10
11
pub struct MemTableIterator {
/// Stores a reference to the skipmap.
map: Arc<SkipMap<Bytes, Bytes>>,
/// Stores a skipmap iterator that refers to the lifetime of `MemTableIterator` itself.
iter: SkipMapRangeIter<'this>,
/// Stores the current key-value pair.
item: (Bytes, Bytes),
}
首先是 key 和 value 方法。可以通过 self.borrow_item() 获取 item 的借用,然后用 0 和 1 索引来获取 key 和 value。1
2
3
4
5
6
7fn value(&self) -> &[u8] {
&self.borrow_item().1[..]
}
fn key(&self) -> KeySlice {
KeySlice::from_slice(&self.borrow_item().0[..])
}
is_valid 方法可以通过判断 key 是否为空来判断。(注意,不能通过 value 是否为空来判断,因为我们的 delete 方法是通过插入空值实现的。)1
2
3fn is_valid(&self) -> bool {
!self.borrow_item().0.is_empty()
}
next 方法需要将「指针」移动到下一个元素。可以通过 with_iter_mut 方法获取 self.iter: SkipMapRangeIter 的可变引用,iter.next 是我们需要将「指针」移动到的地方。但是这样获取到的是 entry 类型,可以封装一个函数将其转换成 item 类型。通过 self.with_mut 方法获取可变引用,并将 iter.next 赋值给 item。1
2
3
4
5
6
7
8
9
10
11fn next(&mut self) -> Result<()> {
fn entry_to_item(entry: Option<Entry<'_, Bytes, Bytes>>) -> (Bytes, Bytes) {
entry
.map(|f| (f.key().clone(), f.value().clone()))
.unwrap_or_else(|| (Bytes::new(), Bytes::new()))
}
let item = self.with_iter_mut(|iter| entry_to_item(iter.next()));
self.with_mut(|x| *x.item = item);
Ok(())
}
Task 2: Merge Iterator
完成 Task1 后,对于多个 memtable 都可以创建其 iterator。现在需要将这些 iterator 合并,并且返回给用户每个 key 最新的版本。这里采用「堆」的数据结构存储每个 memtable 的 iterator。越靠近堆顶的 iterator,存储的数据越新。也就是说,可变 memtable 应该应该在堆顶,不可变 memtable id 越大(越新)就越靠近堆顶。
首先是 MergeIterator 的创建,输入是一组 iterator。它包含两个组成:iters 是堆结构,current 是当前所在的 iterator。
首先判断输入是否为空,如果是,self.iters 直接创建一个新的堆,self.current 置为 None。然后判断这些 iterator 是否均无效。如果都无效,返回的 current 设置为最后一个 iterator。否则的话,将有效的 iterator 压入到堆中,current 就是堆顶的 iterator。
具体实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31pub fn create(iters: Vec<Box<I>>) -> Self {
if iters.is_empty() { // 判断是否为空
return Self {
iters: BinaryHeap::new(),
current: None,
};
}
let mut heap = BinaryHeap::new();
if iters.iter().all(|x| !x.is_valid()) { // 判断这些 iterator 是否均无效
let mut iters = iters;
return Self {
iters: heap,
current: Some(HeapWrapper(0, iters.pop().unwrap())),
};
}
for (i, iter) in iters.into_iter().enumerate() { // 将有效的 iterator 压入到堆中
if iter.is_valid() {
heap.push(HeapWrapper(i, iter));
}
}
let current = heap.pop().unwrap();
Self {
iters: heap,
current: Some(current),
}
}
key 和 value 返回 current 的键值,is_valid 判断 current 是否有效。1
2
3
4
5
6
7
8
9
10
11
12
13
14fn key(&self) -> KeySlice {
self.current.as_ref().unwrap().1.key()
}
fn value(&self) -> &[u8] {
self.current.as_ref().unwrap().1.value()
}
fn is_valid(&self) -> bool {
self.current
.as_ref()
.map(|x| x.1.is_valid())
.unwrap_or(false)
}
next 的实现更加复杂。首先是获取当前 iterator 的借用。不断地取出堆顶元素。由于堆的性质,堆顶元素的 key 一定不小于当前的 key。如果 key 不相等,说明是大于当前元素的第一个元素。否则,说明当前的键值对是较旧版本的,如果无效就 pop 出去,并继续取出堆顶元素。跳出循环后,当前的 current 往后走一步(next),如果无效,直接将堆顶的 iterator 弹出,并替换当前的 current 的 iterator。如果有效,就比较 current 和 堆顶 iterator 的大小(优先级),如果 current 更小(优先级更低),则将 current 与堆顶的 iterator 交换。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43fn next(&mut self) -> Result<()> {
let current = self.current.as_mut().unwrap();
while let Some(mut inner_iter) = self.iters.peek_mut() {
assert!(
inner_iter.1.key() >= current.1.key(),
"heap invariant broken"
);
if inner_iter.1.key() == current.1.key() {
// Case1: Error occurs while calling `next`
if let e @ Err(_) = inner_iter.1.next() {
PeekMut::pop(inner_iter);
return e;
}
// Case2: Iter is not valid
if !inner_iter.1.is_valid() {
PeekMut::pop(inner_iter);
}
} else {
break;
}
}
current.1.next()?;
// if current's iterator is invalid, pop it and go to next one
if !current.1.is_valid() {
if let Some(iter) = self.iters.pop() {
*current = iter;
}
return Ok(());
}
// otherwise, compare the top and swap if nessassery
if let Some(mut inner_iter) = self.iters.peek_mut() {
if *current < *inner_iter {
std::mem::swap(&mut *inner_iter, current);
}
}
Ok(())
}
Task 3: LSM Iterator + Fused Iterator
实现 LsmIterator 的数据结构,能够调用内部的 iterator,并跳过已经删除的键值对。当无效的时候,不应该调用 next,key,value 等方法。
LsmIteratorInner 在目前只包含了一个 MergeIterator 类型的 inner。LsmIterator 的定义中增加一项 is_valid,用来标识当前是否有效。inner 走向下一个元素后判断是否有效,如果无效就修改 is_valid 为 false。1
2
3
4
5
6
7
8
9
10fn next_inner(&mut self) -> Result<()> {
self.inner.next()?;
if !self.inner.is_valid() {
self.is_valid = false;
return Ok(());
}
Ok(())
}
跳过已经被删除的键值对,如果有效且值为空,就一直往后走:1
2
3
4
5
6fn move_to_non_delete(&mut self) -> Result<()> {
while self.is_valid() && self.inner.value().is_empty() {
self.next_inner()?;
}
Ok(())
}
创建新的 LsmIterator,并且需要跳过已经被删除的键值对:1
2
3
4
5
6
7
8
9
10pub(crate) fn new(iter: LsmIteratorInner) -> Result<Self> {
let mut iter = Self {
is_valid: iter.is_valid(),
inner: iter,
};
iter.move_to_non_delete()?;
Ok(iter)
}
接下来实现 StorageIterator 的方法,注意在实现 next 的时候跳过被删除的部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17fn is_valid(&self) -> bool {
self.is_valid
}
fn key(&self) -> &[u8] {
self.inner.key().raw_ref()
}
fn value(&self) -> &[u8] {
self.inner.value()
}
fn next(&mut self) -> Result<()> {
self.next_inner()?;
self.move_to_non_delete()?;
Ok(())
}
FusedIterator 是对现有 iterator 的一层包装,避免用户调用无效的 iterator。因此在调用 next 以及其他方法的时候先判断是否有效:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32fn is_valid(&self) -> bool {
!self.has_errored && self.iter.is_valid()
}
fn key(&self) -> Self::KeyType<'_> {
if !self.is_valid() {
panic!("accessing key/value on an invalid fused iterator")
}
self.iter.key()
}
fn value(&self) -> &[u8] {
if !self.is_valid() {
panic!("accessing key/value on an invalid fused iterator")
}
self.iter.value()
}
fn next(&mut self) -> Result<()> {
if self.has_errored {
bail!("calling next on an fused iterator after error")
}
if self.iter.is_valid() {
if let Err(e) = self.iter.next() {
self.has_errored = true;
return Err(e);
}
}
Ok(())
}
Task 4: Read Path - Scan
实现 LSM 引擎的 scan 路径。首先获取当前状态的快照。创建一个 Vec 存储当前的 memtable,依次将可变与不可变的 memtable 加入到 Vec 中。传入 Vec 创建 MergeIterator。最后将 MergeIterator 包装在 LsmIterator 中返回,再包装在 FusedIterator 中返回。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/// Create an iterator over a range of keys.
pub fn scan(
&self,
_lower: Bound<&[u8]>,
_upper: Bound<&[u8]>,
) -> Result<FusedIterator<LsmIterator>> {
let snapshot = Arc::clone(&self.state.read());
let mut memtable_iters = Vec::with_capacity(snapshot.imm_memtables.len() + 1);
memtable_iters.push(Box::new(snapshot.memtable.scan(_lower, _upper)));
for imm_memtable in snapshot.imm_memtables.iter() {
memtable_iters.push(Box::new(imm_memtable.scan(_lower, _upper)));
}
let memtable_iter = MergeIterator::create(memtable_iters);
Ok(FusedIterator::new(LsmIterator::new(
memtable_iter,
)?))
}
Result
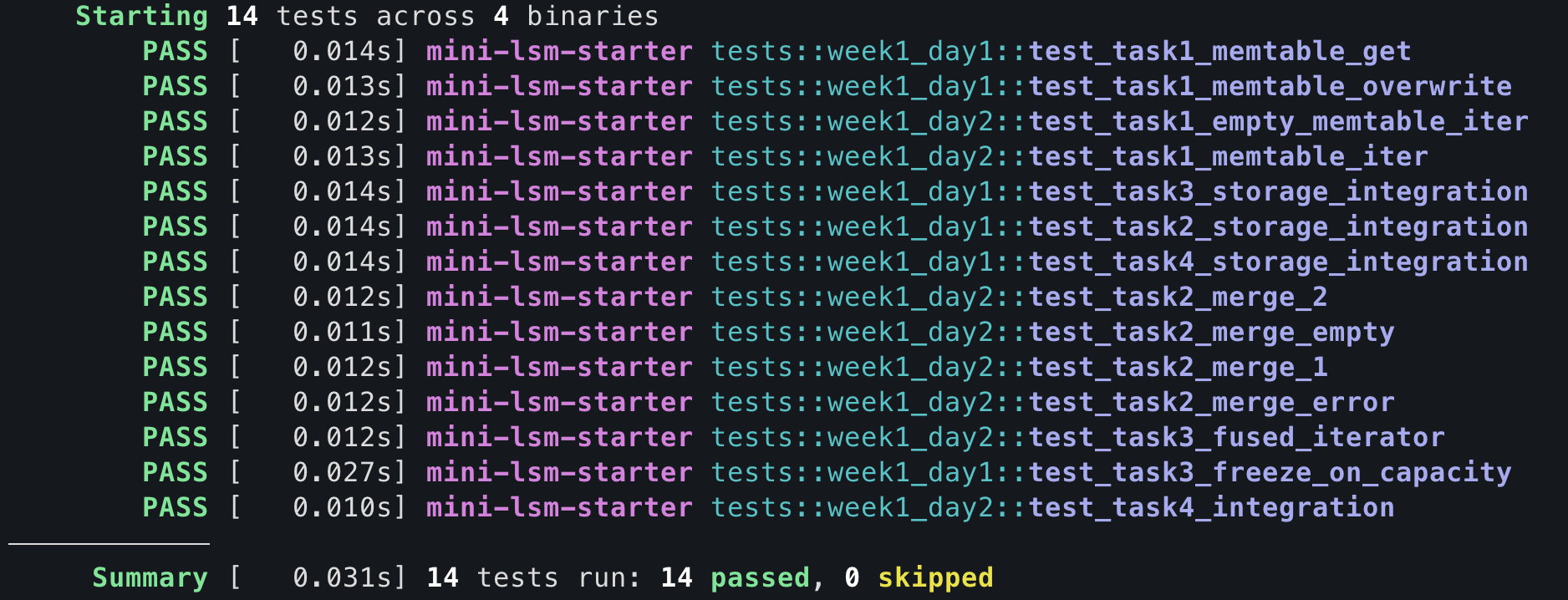
Test Your Understanding
What is the time/space complexity of using your merge iterator?
Merge iterator的创建的时间复杂度就是建堆的时间复杂度,也就是 \(O(n\log n)\)。Why do we need a self-referential structure for memtable iterator?
为了确保 iterator 和结构中的 map 的生命周期一致。If a key is removed (there is a delete tombstone), do you need to return it to the user? Where did you handle this logic?
如果键被删除了,是不需要返回给用户的。在LsmIterator中,通过move_to_non_delete方法跳过被删除的键值对。If a key has multiple versions, will the user see all of them? Where did you handle this logic?
不会,只会返回最新版本的结果。通过比较堆顶 iterator 和当前 iterator 的 key,如果相等就继续往下走。If we want to get rid of self-referential structure and have a lifetime on the memtable iterator (i.e., MemtableIterator<’a>, where ’a = memtable or LsmStorageInner lifetime), is it still possible to implement the scan functionality?
可以实现,核心思路就是通过将 ’a 生命周期从 LsmStorageInner 传递到所有迭代器组件,确保所有引用在存储引擎生命周期内有效。What happens if (1) we create an iterator on the skiplist memtable (2) someone inserts new keys into the memtable (3) will the iterator see the new key?
不会看到新的键,因为获取的是当前状态的快照。What happens if your key comparator cannot give the binary heap implementation a stable order?
如果比较器不能给堆实现稳定的顺序,那么堆可能无法正确排序,可能会导致返回的键值对不是最新版本的键值对。Why do we need to ensure the merge iterator returns data in the iterator construction order?
为了确保返回的键值对是按照插入顺序返回的,也就是为了保证返回的是最新的键值对。Is it possible to implement a Rust-style iterator (i.e., next(&self) -> (Key, Value)) for LSM iterators? What are the pros/cons?
可以,但是需要额外的包装。优点是可以直接返回键值对,不需要额外的调用。缺点是会增加额外的开销。The scan interface is like fn scan(&self, lower: Bound<&[u8]>, upper: Bound<&[u8]>). How to make this API compatible with Rust-style range (i.e., key_a..key_b)? If you implement this, try to pass a full range .. to the interface and see what will happen.
使用 RangeBounds 泛型来实现,内部将 Rust 范围转换为存储引擎所需的 Bound<&[u8]>。The starter code provides the merge iterator interface to store Box< I> instead of I. What might be the reason behind that?
主要是为了隐藏泛型 I 的具体实现,避免在代码中暴露太多 generics。同时确保生命周期的统一。