SGLang 创新性地提出了基于压缩有限状态机的跳跃式解码方法,相比于传统的有限状态机,实现了显著的性能提升。
背景
在 LM 编程中,用户有时候会希望约束模型的输出格式,比如以 JSON 的格式输出。特定的输出格式可以更加方便地解析结果。
方法
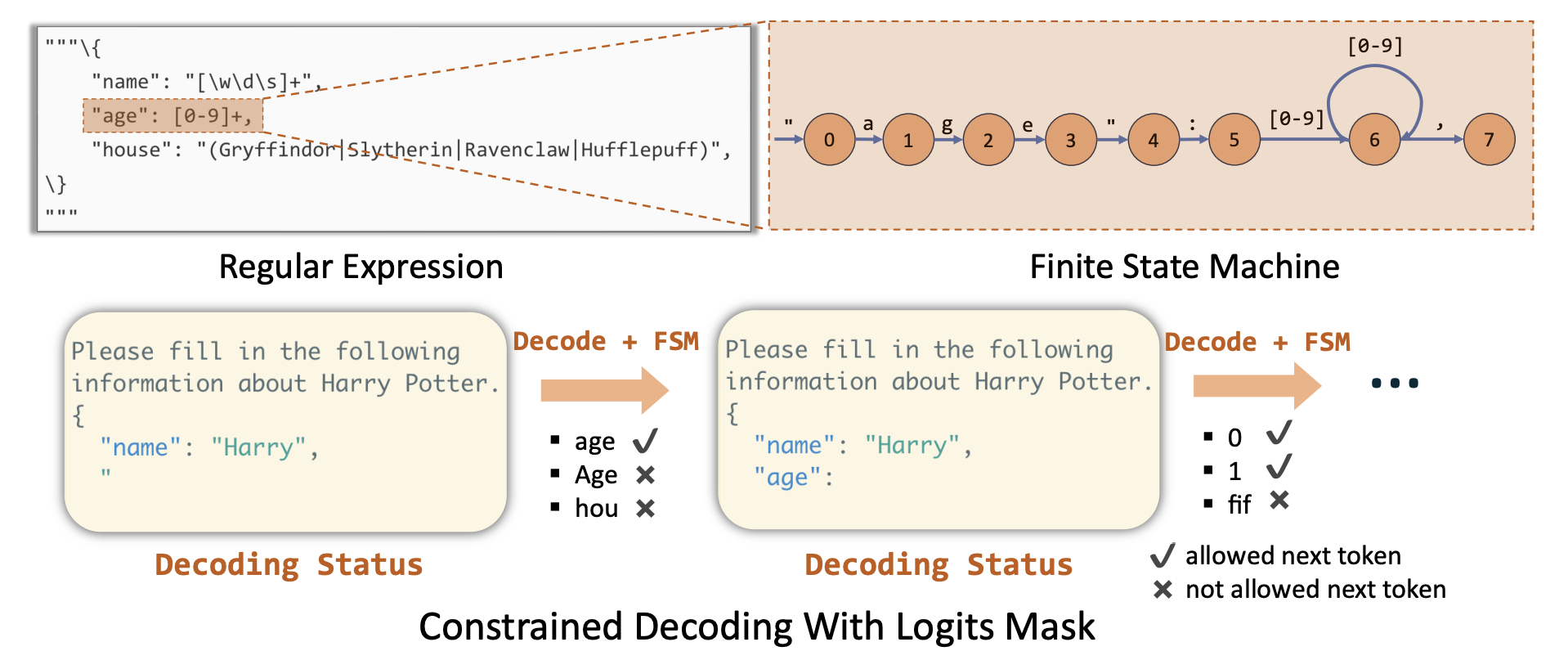
普通的基于有限状态机(FSM)的方法需要先将 JSON 模式转换成正则表达式,然后根据正则表达式构建 FSM。FSM用于引导 LLM 的生成。在 FSM 的每一个状态中,我们可以计算允许的转换,并且识别可以被接受的 token。也就是说在 decode 的过程中跟踪当前状态,通过对输出应用 logit 偏差过滤不符合的 token。
以下图为例,要求生成 age 的字段。首先将 JSON 模式转换成对应的表达式,因为 age 字段只能是自然数,即:1
2
3"age": {
"type": "Integer" --> "age": [0-9]+
}
而 SGLang 提出的基于压缩有限状态机的跳跃式解码方法就是为了解决推理一次只能生成一个 token 的问题。本质就是一次产生多个 token 的方法。概括地说,其操作步骤主要包括以下两步: - 维护当前的 FSM 状态,从下一个状态中检索允许的 token,并将无效的 token 概率置为 0; - 运行时分析 FSM,将 FSM 中相邻的单一转换边压缩成单一边,使其能够识别何时可以一起解码多个 token。这样可以直接预填这些单一路径,跳过逐 token 解码,直到下一个分支点。
下图是与普通有限状态机解码的对比。例如在为 house 字段生成值时,模型根据「G」直接生成了 「ryffinfor」这个字符串,而无需逐字符地去生成。这样既可以提高 decode 效率,也可以避免不必要的计算。具体而言: - 输入提示:图中左侧的绿色部分,提示模型生成一个符合 JSON 模式的对象,包括 name、age 和 house 字段; - 跳跃前进解码:中间上半的蓝色和橙色部分 - 橙色部分表示约束解码的部分,比如 「name」这个字符串可以根据上下文比较准确地预测,因此可以直接生成 - 蓝色部分表示逐 token 解码的部分,只有在遇到非确定性、多个可能值的时候才会出现 - 普通解码:中间下半的蓝色部分,逐个 token 预测,效率较低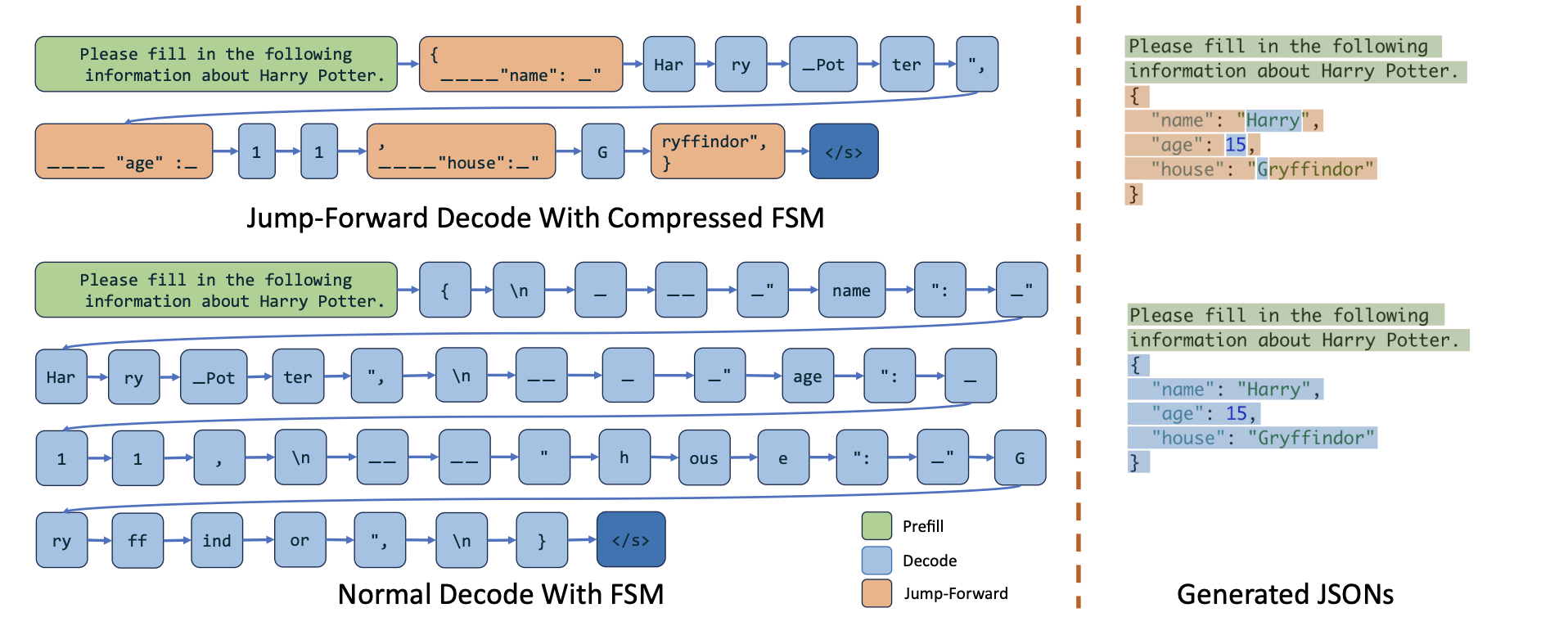
实验表明在受限解码任务上比 Outlines+vllm 和 Guidance+llama.cpp 速度提升了约 2.5 倍。
缺陷是字符串和 token 之间的差距会导致概率分布的不均衡。比如对于正则表达式 [ABCD][+-]? 表示的是成绩从 D- 到 A+,但是如果对于更加宽泛的评价标准比如 「Excellent|Above Average|Fair|Below Average」,可能会因为压缩边,直接将 A 映射到 Above Average。这是因为 LLM 没有识别出选择的具体范围,导致生成了不恰当的序列。